

Высокопроизводительный инференс-сервис GiEngine
Инновационный инференс-сервис GiEngine обеспечивает запуск и применение большинства моделей GitLife AI с открытым исходным кодом, освобождая компании от трудоёмкого процесса развёртывания моделей. По сравнению с традиционными выделенными инференс-решениями, стоимость вычислительных ресурсов существенно снижается.

ADVANTAGE
Преимущества решения
Простое развёртывание и использование
Быстрое приватное развёртывание с минимальной настройкой. Стандартный открытый API для лёгкой интеграции с исследовательскими и прикладными AI-решениями
Поддержка ключевых типов моделей
Работа с многоязычными и мультимодальными моделями. Поддержка различных сценариев применения: диалоговые системы, вопросно-ответные системы, генерация резюме, машинный перевод, извлечение эмбеддингов и другие задачи
Совместимость с различными аппаратными платформами
Помимо Nvidia поддерживает российские и азиатские вычислительные платформы: Тяньшу Чжисинь, Муси, Хуавэй Шэнтэн, Чжункэ Шугуан и другие, обеспечивая производительность, сравнимую с Nvidia
FEATURES
Технические характеристики
Универсальные интерфейсы доступа
Высокопроизводительный инференс-сервис GiEngine предоставляет два основных уровня интерфейсов для работы с различными моделями.
Web API
Native Python Library
Web-интерфейсы, совместимые с OpenAI API, обеспечивают лёгкую интеграцию с экосистемами с открытым исходным кодом: Diify, LangChain, LobeChat и другими
curl https://ai.gitee.com/v1/chat/completions \
-X POST \
-H "Authorization: Bearer ${API_TOKEN}" \
-H "Content-Type: application/json" \
-d '{"model":"Qwen2.5-72B-Instruct","stream":true,"max_tokens":512,"temperature":0.7,"top_p":0.7,"top_k":50,"frequency_penalty":1,"messages":[{"role":"user","content":"树上9只鸟,打掉1只,还剩几只?"}]}'
Стабильная производительность инференса
В высокопроизводительном инференс-сервисе GiEngine каждый API-токен соответствует выделенному каналу инференса с гарантированной производительностью.
- Изоляция каналов инференса обеспечивает независимость производительности, данных и безопасности.
- Запросы, отправленные с одним API-токеном, помещаются в очередь в выделенном канале инференса.

Эффективное серверное кэширование
Высокопроизводительный инференс-сервис GiEngine включает многоуровневую систему кэширования, оптимизированную под алгоритмы моделей. Это позволяет эффективно использовать иерархическую гетерогенную память и сократить количество повторных вычислений в процессе инференса.

Поддержка адаптеров LoRA
Высокопроизводительный инференс-сервис GiEngine поддерживает применение адаптеров LoRA в режиме реального времени, что позволяет быстро адаптировать крупные модели под специфические задачи без необходимости полной переподготовки.
TECH HIGHLIGHTS
Ключевые технические особенности
Архитектура системы
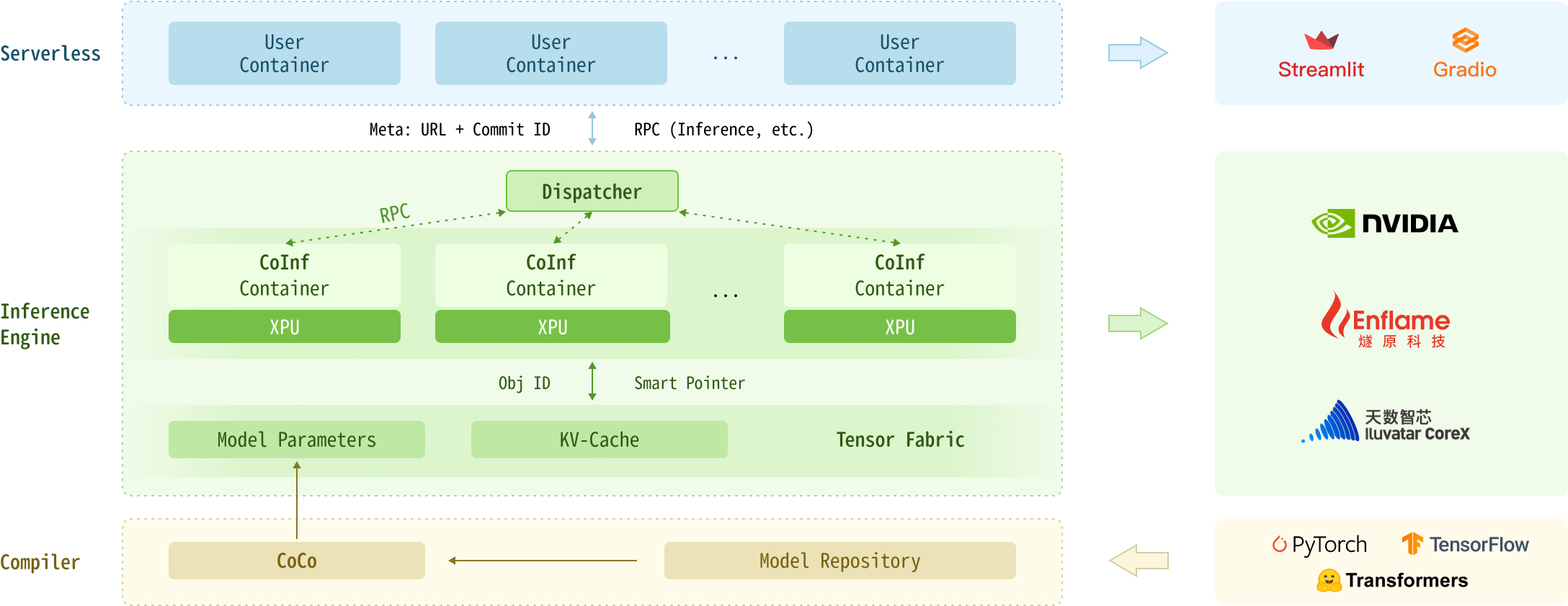
Оптимизация времени исполнения
Поддержка нескольких алгоритмических моделей и фреймворков с оптимизацией эффективности исполнения моделей


Поддержка различных аппаратных ускорителей
Интеграция с широким спектром вычислительных платформ: от Nvidia до российских и азиатских решений, включая Суйюань, Тяньшу Чжисинь, Чжункэ Шугуан, Муси и Шэнтэн
Если вас заинтересовал высокопроизводительный инференс-сервис GiEngine, отправьте запрос на адрес support@gitlife.ru. Мы оперативно свяжемся с вами для предоставления детальных технических характеристик и условий обслуживания. Будем рады сотрудничеству!
Попробовать сейчас